Systemic risk in software engineering is the inherent risk that exists within any complex digital business systems. It’s the threat of risk spreading into a business from connected third-parties or out of your business into others. It’s also the threat of one component going down, which then cascades, crippling through the entire system. That’s the story how Facebook disappeared from the Internet on October 5th 2021 or how Java services can be exploited remotely by a vulnerability in Log4j recently.
As engineering managers, we all want to effectively control systemic risks that may affect our software systems. The problem is you may see an incomplete view of risks in a web of intricately linked systems. That’s is: you to only see the tree but not the forest. Even if you try to see many trees as possible, the forest itself is not simply a collection of such trees.
There’s an old saying that “Two heads are better than one”. Good news is you have more-than-two heads in your team & we can work collectively to manage risks early & often.
“Given enough eyeballs, all bugs are shallow”, Linus’s law
Risk Management
Risk Management Guide for Information Technology Systems from NIST shows a practical process to adopt. The guide is a little bit security inclined. Not all our systemic risks relate to security.
At a large scale, device or communication failures are quite common. Your systems may incorrectly handle such risks resulting in inaccessibility and inconsistency in data. It is a fundamental problem in Computer Science named as Consensus
Broadly speaking, a systemic risk is any hazard can make users incorrectly access their data in terms of CIA triad:
- Confidentiality: only authorized users have access to a specific data.
- Integrity: user data can be stored correctly & securely. So there’s no illegal modification from hackers, insiders. Under network failures, systems still have a consistent view of the data.
- Availability: authorized users can access their data in a timely manner, any time, any where. By
timelyI mean, end-user APIs should have p99 latency under 200ms (or smaller). This will have a positive impact on User Experience. Amazon found that just 100 milliseconds of extra load time cost them 1% in sales.
The triad is rooted in Information Security and fortunately we still blend it into a more broad view of distributed systems. The Risk Assessment process could be customized to suit this new view.
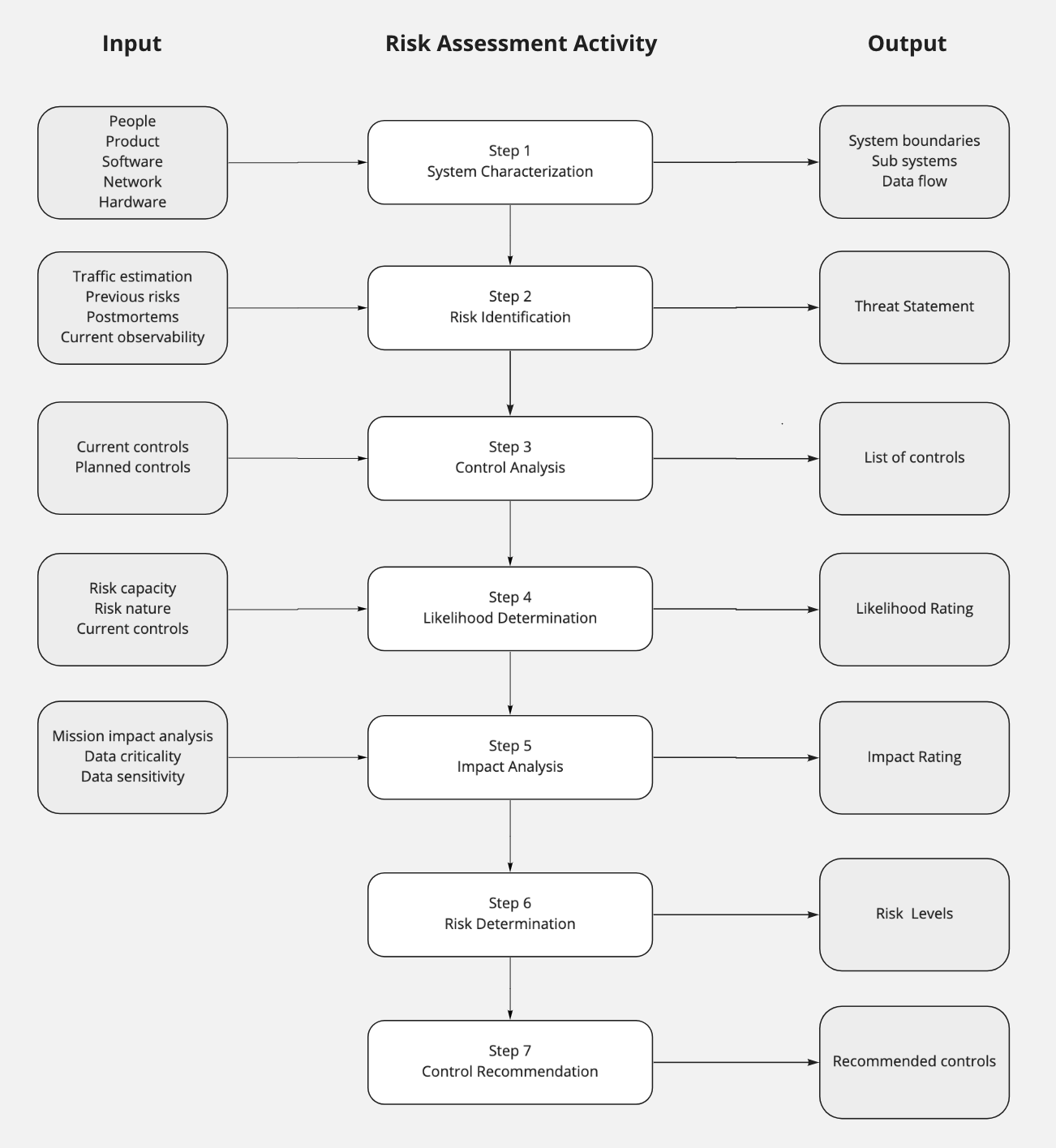 A customized Assessment Process for NIST’s Risk Management Guide
A customized Assessment Process for NIST’s Risk Management Guide
Build to mitigate risks early
Critical distributed systems require a thoughtful approach in design. Such systems have instances running on multiple physical nodes communicating via network calls. And it’s tricky to handle such calls right.
Having shared knowledge on Distributed Systems is valuable while we collaboratively design systems to tackle such risks early on. A member has the total ownership on a feature. He then proposes a design doc for team to review in meetings.
We ask a lot of constructive questions from different angles: What if Redis fails? What if we have late events?… Each unanswered question will lead to another update in the doc, another meeting to discuss. We answer all of them before writing any code.
Design as a team; implement as individuals
Premature Optimization Is the Root of All Evil. Sometimes we have to make a trade-off. For example: Redis is a popular caching solution we use. Deployed as a cluster, Redis provides some degree of availability during partitions. But partitions can result in Split-brain scenarios, cached data can be inconsistent between masters and replicas. And we decided to favor data consistency over data availability by deploying more replicas and having a more appropriate configuration.
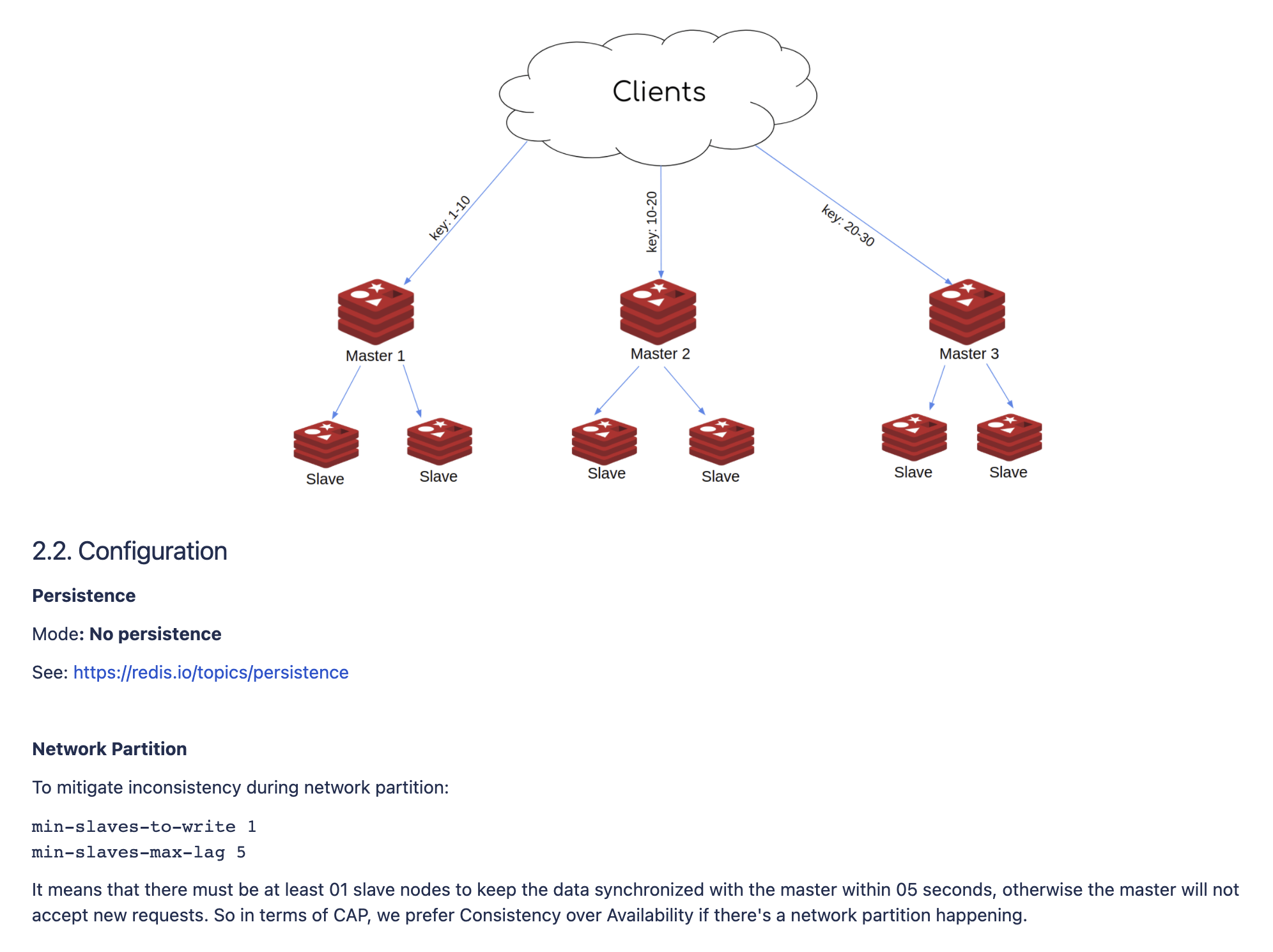 A Design Doc from one of our projects
A Design Doc from one of our projects
On the other hand, we follow Chaos engineering discipline to actively inject faults into systems to see if they work under rigorous conditions. Previously we customized Jepsen to run chaos tests. It’s a well-known framework for verifying distributed systems esp. database ones. But the learning curve is a little bit steep. Not all our engineers know how to write a test with Clojure. Recently we’ve adopted Chaos Mesh and found it a great relief. Now every member can run chaos tests on their own.
Review often
Our systems together exist with other ones to fulfill requests from users & business. By working backward, cooperatively we work with other teams to review entire execution flows periodically. From my experience, using online collaboration applications makes this process more fun with many unexpected views from members.
 A review session
A review session
The output from Review sessions will be populated in a document with tracking issues accompanied.
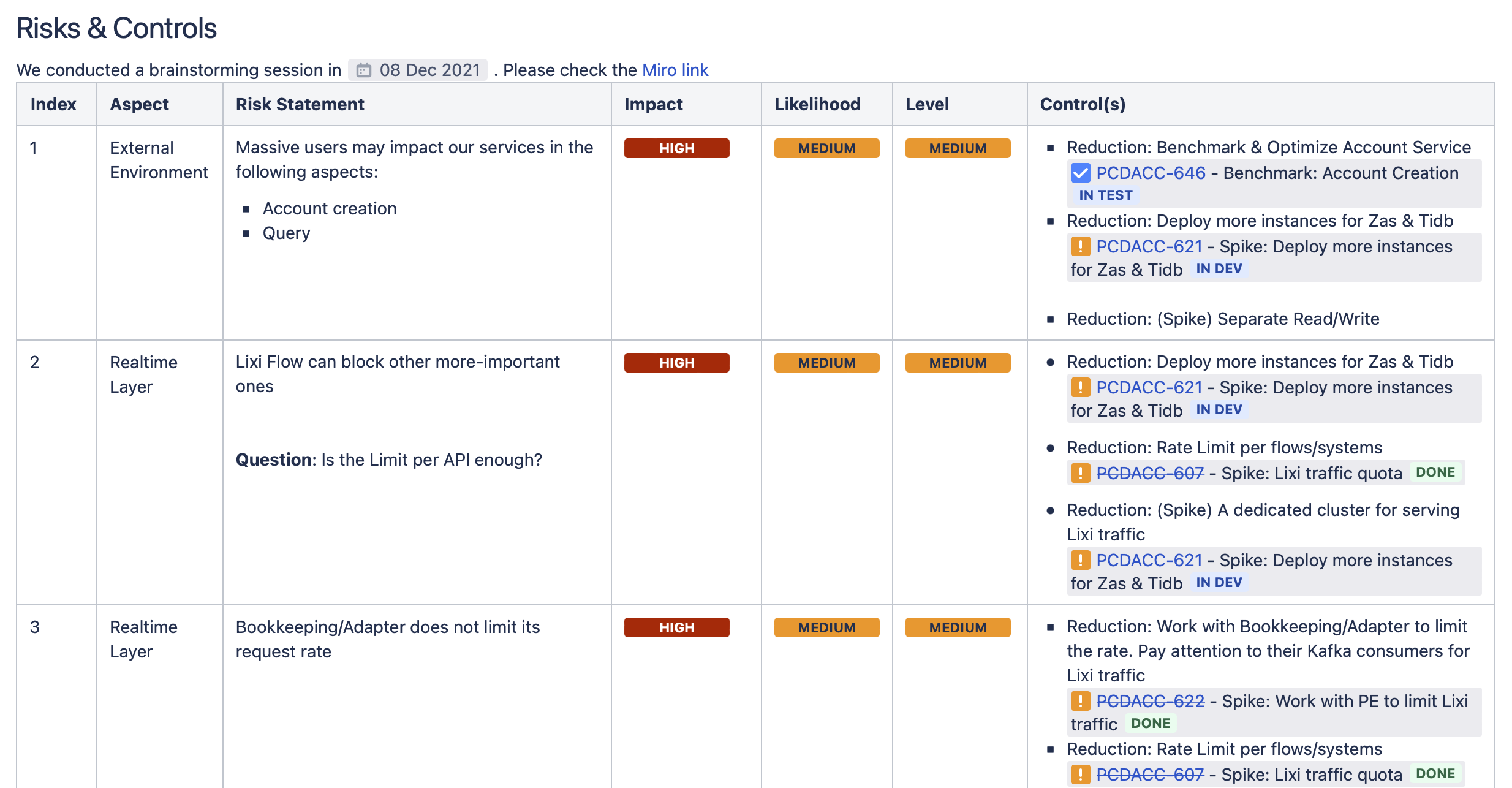 Risks and Controls
Risks and Controls
Final Thought
Sometime your systems may fail to address an unidentified risk. This would lead to unwanted incidents. It is unavoidable because everything is ever evolving, including risks. Let such unidentified a lesson cost so much to learn.
As an engineering manager, you’re mainly responsible for incidents. By openly sharing such valuable lessons with members, we foster a culture of risk-taking which is crucial to Innovation.
What’s your view on this topic? I’m glad to hear any feedback.